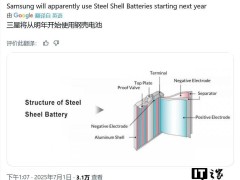
華為在近期的一次重要宣布中,正式揭開了其在大模型技術(shù)領(lǐng)域的又一里程碑。此次,華為不僅推出了盤古70億參數(shù)的稠密模型,還帶來了盤古Pro MoE這一擁有720億參數(shù)的混合專家模型,并配套發(fā)布了基于昇騰的模型推理技術(shù)。
這一系列的開源舉措,被視為華為在推動昇騰生態(tài)戰(zhàn)略實施過程中的又一重要步驟。通過這些努力,華為旨在加速大模型技術(shù)的創(chuàng)新與發(fā)展,進一步拓寬人工智能技術(shù)在各行各業(yè)的應(yīng)用邊界,從而創(chuàng)造更大的價值。
目前,盤古Pro MoE 72B模型的權(quán)重和基礎(chǔ)推理代碼已經(jīng)成功上線至開源平臺,供全球開發(fā)者免費下載和使用。與此同時,基于昇騰的超大規(guī)模MoE模型推理代碼也已同步上線,為開發(fā)者提供了強大的推理能力支持。
值得注意的是,盤古7B的相關(guān)模型權(quán)重與推理代碼也即將在近期上線開源平臺。這意味著,開發(fā)者將能夠擁有更多選擇,根據(jù)實際需求選用不同規(guī)模和性能的模型。
在華為此次推出的模型中,盤古Embedded 7B模型以其獨特的雙系統(tǒng)框架和元認知能力脫穎而出。該模型能夠根據(jù)任務(wù)復(fù)雜度自動切換推理模式,從而在保證推理速度的同時,兼顧推理深度。在多項復(fù)雜推理基準測試中,盤古Embedded 7B模型的表現(xiàn)甚至超越了同量級的Qwen3-8B和GLM4-9B等模型。
而盤古Pro MoE 72B模型則采用了分組混合專家(MoGE)架構(gòu),總參數(shù)量高達720億,但激活參數(shù)量僅為160億。這一設(shè)計有效解決了專家負載不均的問題,提高了模型的部署效率。同時,針對昇騰硬件的深度優(yōu)化,使得該模型在推理速度上達到了新的高度,最高單卡可達1528 tokens/s。在多項公開基準測試中,盤古Pro MoE 72B模型均表現(xiàn)出色,性能優(yōu)于同規(guī)模的稠密模型。
華為官方表示,他們誠摯邀請全球的開發(fā)者、企業(yè)伙伴及研究人員下載并使用這些模型,同時期待收到大家的寶貴反饋,以便共同完善和提升這些技術(shù)。