近期,科技界傳來一項新進展,谷歌DeepMind團隊推出了一項名為QuestBench的全新基準測試,旨在評估大型語言模型(LLMs)在推理任務中識別和填補信息缺口的能力。這一創新舉措針對現實世界中信息不完整的問題,為LLMs的發展提供了新的挑戰與機遇。
在各類推理任務中,如數學、邏輯、規劃和編碼等領域,大型語言模型正受到越來越多的關注。然而,實際應用場景往往伴隨著大量的不確定性,例如用戶提問時可能遺漏關鍵信息,或機器人等自主系統需要在部分可觀測的環境中運行。這種理想與現實之間的差距,使得LLMs必須發展出主動獲取缺失信息的能力。
QuestBench基準測試正是為了應對這一挑戰而生。它采用約束滿足問題(CSPs)的框架,特別關注“1-sufficient CSPs”,即只需一個未知變量的信息即可解決目標變量的問題。該測試覆蓋了邏輯推理、規劃和小學數學三個領域,通過變量數量、約束數量、搜索深度和暴力搜索所需猜測次數四個維度,對模型的推理策略和性能瓶頸進行精準評估。
據悉,QuestBench已經對包括GPT-4o、Claude 3.5 Sonnet、Gemini 2.0 Flash Thinking Experimental等在內的多個領先模型進行了測試,測試環境涵蓋了零樣本、思維鏈和四樣本設置。測試結果顯示,思維鏈提示在提升模型性能方面發揮了普遍作用,而Gemini 2.0 Flash Thinking Experimental在規劃任務中展現出了最佳表現。
開源模型在邏輯推理方面表現出了一定的競爭力,但在處理復雜的數學問題時則顯得力不從心。研究指出,盡管當前模型在解決簡單代數問題上表現尚可,但隨著問題復雜性的增加,其性能顯著下降。這一發現揭示了LLMs在信息缺口識別和澄清能力方面仍有較大的改進空間。
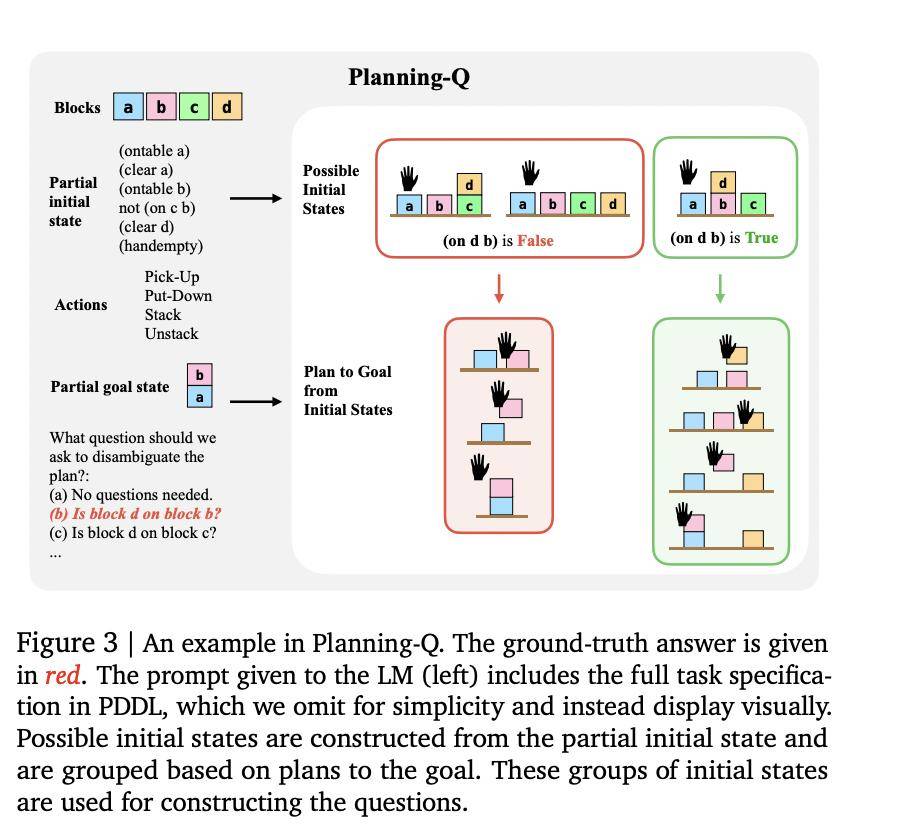
QuestBench基準測試的推出,不僅為評估LLMs在推理任務中的性能提供了新的工具,也為推動LLMs在信息獲取和推理能力方面的發展指明了方向。隨著技術的不斷進步,我們有理由相信,未來的LLMs將能夠更好地應對現實世界中的不確定性,為人類提供更加準確和可靠的解決方案。
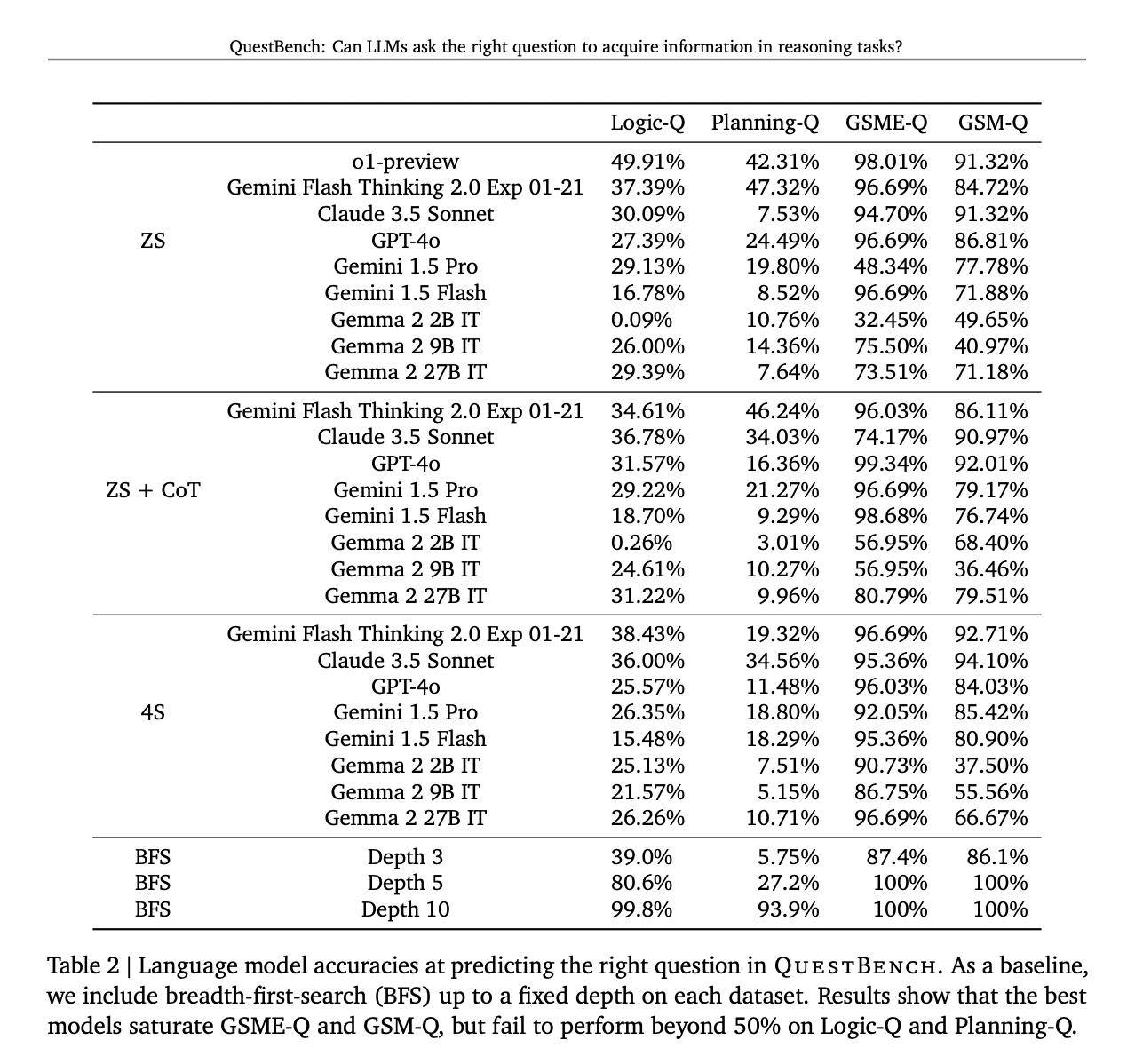
QuestBench測試還涵蓋了288個GSM-Q和151個GSME-Q任務,這些任務的設計充分考慮了現實世界的復雜性,使得測試結果更加貼近實際應用場景。通過這一基準測試,我們可以更加清晰地了解LLMs在不同領域和難度下的表現,從而為模型的進一步優化和改進提供有力支持。